Di part 1 sudah dibahas gimana kata yang kita masukan sebagai prompt ditokenisasi sampai akhirnya tiap token tersebut memndapatkan id yang kemudian ditukar ke vektor embedding berupa deretan 4096 koordinat
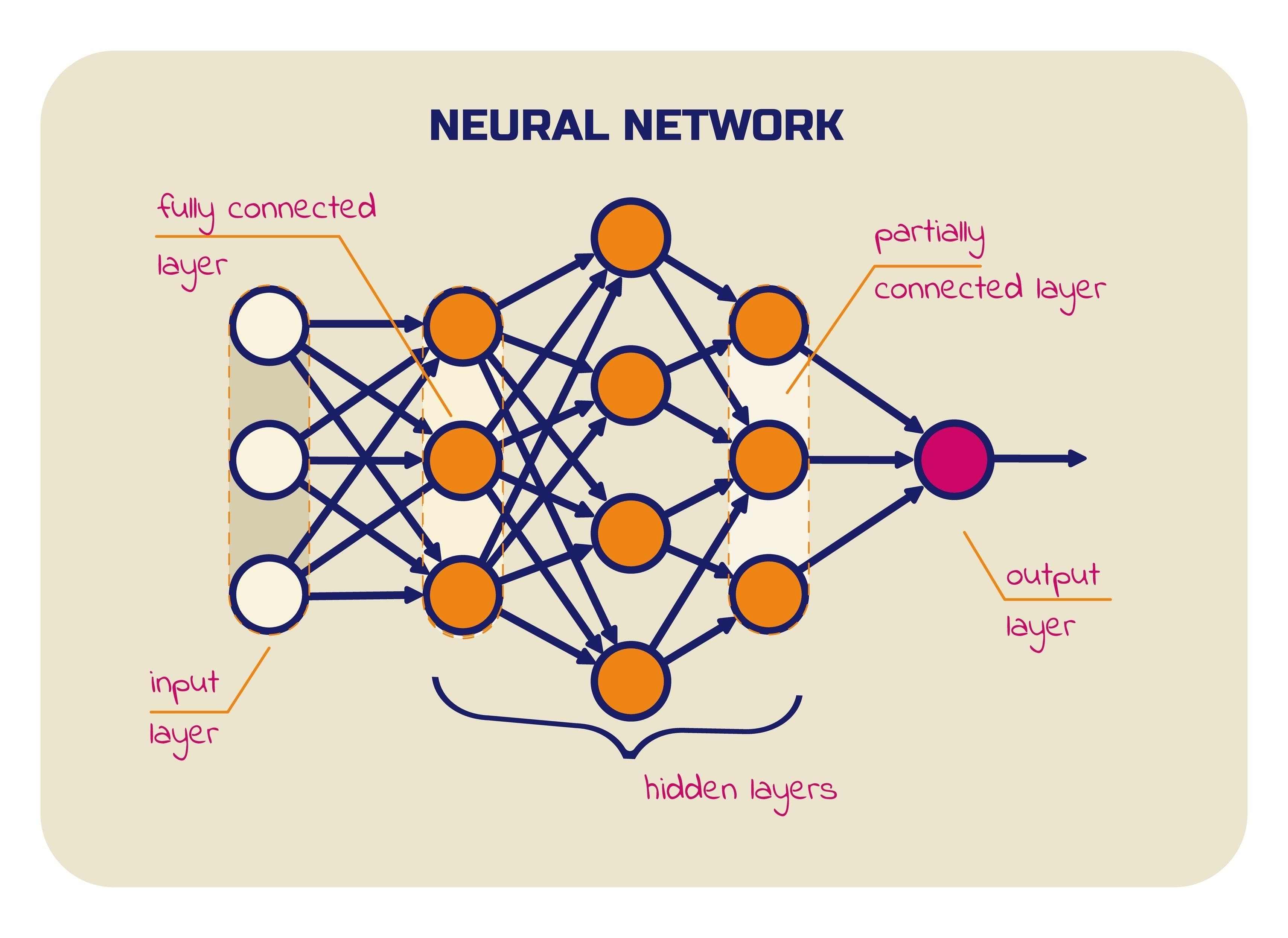
lalu setelah jadi vektor embeding gimana proses selanjutnya yang terjadi di dalamnya ?, ada 2 komponen penting yang bekerja di sini yaitu jaringan saraf (deep layers) dan parameter (weight & biases)
- parameter ibarat papan dj raksasa yang punya miliaran tombol untuk atur volume suaranya , biasanya saat llm rilis ke publik mereka akan flexing berapa billion parameter yang digunakan, apa parameter itu ? dalam matematika, parameter di dalam Neural Network terdiri dari 2 hal :
- weights (bobot) adalah angka pengali untuk menentukan seberapa penting suatu informasi
- biases (bias) adalah angka konstan penambah untuk menyetel sensitivitas tebakan
nah parameter ini adalah miliaran angka pengali yang sdah paten (dikunci) yg diperoleh saat proses training model hasi dari membaca internet (yang menebak kata selanutnya itu), saat user bertanya koordinat yg tadi sudah didapat dari tokenisasi id akan disaring dan dikalikan dengan miliaran tombol ini
- struktur berlapis (deep layers) vektor koordinat tadi tidak hanya dikalikan sekali namun ada puluhan hingga ratusan layers jaringan siber yang ditumpuk secara vertikal , pada saat koordinat kata melewati lapisan2 tsbt , terjadi pembagian tugas di sana :
-
lapisan bawah (early layers) berfokus pada struktur fisik teks (tata bahasa) : pada tahap ini parameter bekerja untuk mengenali subjek, objek dan hubungan antarkata. misal mengunci bahwa angka 3 itu berpasangan dengan kata butir telur apabila pertanyaan user : apakah protein hari ini saya cukup? saya konsumsi 3 telur hari ini .
-
lapisan tengan : middle layers di sini dia memahami konteks abstrak (semantik). parameter pada lapisan ini akan menarik koordinat kata telur dan protein ke zona baru bernama zona informasi gizi / nutrisi, karna AI tahu kedua kata ini punya hubungan erat di dunia nyata (setelah koordinatnya dikalikan oleh parameter di lapisan ini)
-
lapisan atas (deep layers) : merumuskan konsep jawaban . koordinat dari seluruh kalimat yg ditanyakan user diperas jadi satu titik koordinat final yang mengandung kesimpulan conoth kasus pertanyaan tadi : “user butuh konfirmasi kecukupan gizi dari makanan yang disebut”.
- Ujung lapisan : menembak skor kamus (softmax) di akhir lapisan lapisan tersebut ai menghasilkan satu koordinat final 4096 dimensi yang isinya “ide jawaban” tapi komputer harus kembali konvert koordinat ini kembali jadi kata yang bisa dibaca manusia, prosesnya dinamakan dengan softmax
- koordinat final dicocokan dengan seluruh kata (misal 100.000 token) yang ada di kamus raksasa ai
- proses ini menghasilkan skor probabilitas untuk setiap kata di kamus
contoh kasus pertanyaan telur tadi akan muncul persentase seperti ini misal:
- token “ĠTiga” -> probabilitas 45.0% persentae paling tinggi
- token “ĠBerdasarkan -> probabilita 30.0%
- token “ĠKucing” -> probabilitas 0.00001%
karena token “ĠTiga” mendapatkan persentase tertinggi , sistem akan memilih kata tersebut untuk dimunculkan ke pengguna sebagai kata pertama dari jawaban ai.
nanti kata tiga akan di evaluasi lagi ditambah dengan konteks pertanyaan pengguna, akan terus iterasi sampai ada tanda berakhir (ini perlu dibahas nanti kenapa kapa saatnya kenapa ai tahu kapan harus stop)
Ġ ini token spasi yg dipahami oleh llm